
本项目仓库:GitHub:WFACat
整个项目技术细节见下面总结列出的博文。
一 想法
通过微博抓取微博好友,然后抓取好友的好友,以自己到直接好友为一度人脉,依次类推。/ 社交关系网络的构成是节点和边,人物就是节点,边(连线)即是关系。即为 source、target。
分析问题复杂度,为简单,化简为只抓取互相关注的(微博客户端用户粉丝里可直接看到相互关注的),这也符合常理,通常相互关注的更可能是好友关系。假设每个人互关的好友数是常数 a = 20 人,那么一共要抓取的人数(总数关系的数据量)y 是人脉度数 x 的幂函数。一度人脉一个乘号,假设 2 度人脉,每个人互关好友 20 人,即 y = 20 x 20 = 400。这个数据量还可以接受。所以决定抓取二度人脉进行分析。考虑到二度人脉做可视化分析、爬取难度等方面比较合适。
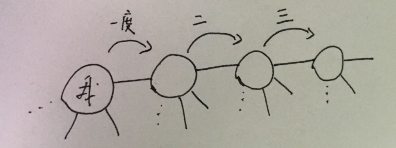
步骤:
先抓取用户信息,然后对原始数据进行分析。问题细化:
- 怎样模拟登陆微博,要不要考虑 IP 地址被禁问题
- 怎样抓取到数据
- 需要抓那些数据
- 数据存放在哪、怎样存放
- 怎样对数据清洗筛选
- 用什么工具、怎样分析数据得出有价值的结论
二 参考资料
- Gephi 官方教程
- GEPHI中文教程
- Gephi 入门使用
- 介绍用Gephi进行数据可视化
- Gephi网络图极简教程
- Website login model
- Weibo_Comment_Pics 爬取
- 爬虫(三)生成qq好友关系网(1)—登录并获得好友列表
- 【轻量级微博爬虫】自动爬取用户信息及微博内容(2019年3月可用)
- 从0写一个爬虫,爬取500w好友关系数据
- Python新浪微博爬虫-1 爬取评论、用户名、用户ID
- 新浪微博爬虫分享(一天可抓取 1300 万条数据)
- 使用python进行新浪微博粉丝爬虫
- 微博社交网络图:爬虫+可视化
三 需求分析与设计
- 需求分析:
- 相互关注列表关系(标记第几度人脉)
- 微博 id
- 链接
- 性别
- 关注数、粉丝数
- 地点
- 个性签名
- 微博数
- 设计:
- 模拟登陆或其它能抓取到数据的前提。
- 从自己的账号下开始,获取相互关注列表中第一个用户,记录下信息,此列表中的用户标记为一度人脉,标记是谁的好友(来源)。
- 按照一度人脉列表中第一个,去爬二度人脉的互关列表,记录下列表中每个用户信息。
- 返回到一度人脉列表中第二个,依次递归下去。
- 数据分析:
- 因为使用 Gephi 数据可视化软件来分析关系,Gephi 需要规定的格式。所以先把原始数据全存到 MySQL 中,然后从中导出 Gephi 需要的格式。
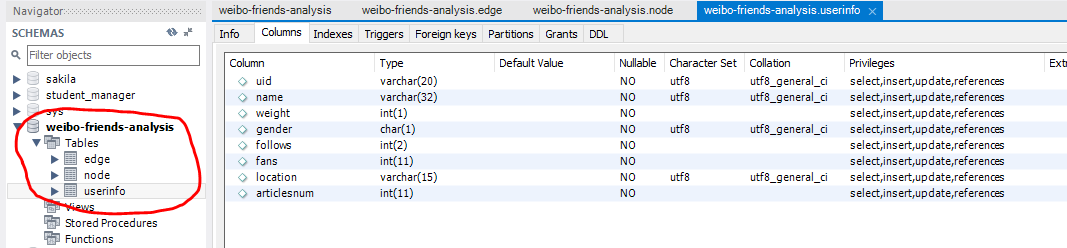
- MySQL 数据库设计:分为三张表,两张表用来存放人际关系。另一张表用来存放每个用户的详细信息。
四 实践过程
1 方案一:使用数据库
为什么要用数据库,用 CSV 也可以分析好友关系。用数据库可以更方便存储更多的用户信息。
使用 MySQL,设计三张表,用 MySQL 图形界面完成操作。
创建数据库:
CREATE DATABASE weibo-friends-analysis;好友关系表,因为要使用 Gephi 进行可视化分析,所以要注意表的设计。/ 以分析社交网络为例。分为两个表,一个表叫 Node,另一个叫 Edge。/ 然后写代码等方式收集数据写入数据库。
- Node 表属性:Id、Label。分别为微博用户的唯一 id、微博用户名
- Edge 表属性:Source、Target、Weight。分别为两个用户,表明两个用户间的关系。Weight 表示第几度人脉。
1 | CREATE TABLE `weibo-friends-analysis`.`node` ( |
- 用户信息表:
userinfo 表属性有:uid、name(微博名)、weight(第几度人脉)、gender、follows、fans、location、articlesnum。
1 | CREATE TABLE `weibo-friends-analysis`.`userinfo` ( |
数据库已经创建好:
获取数据,然后分析 json 文件,将信息提取后写入 MySQL,然后做数据分析。/ 怎样爬信息参见我的博文 《通过微博手机客户端爬取数据的分析》。
2 方案二:使用 CSV
获取数据,然后分析 json 文件,将信息提取后写入 CSV 文件,然后做数据分析。/ 怎样爬信息参见我的博文 《通过微博手机客户端爬取数据的分析》。
写入 CSV 文件方法:[Python3网络爬虫开发实战] 5.1.3-CSV文件存储。/ 两个 CSV 文件:Node 文件(Id、Label)。分别为微博用户的唯一 id、微博用户名;Edge 文件(Source、Target、Weight)。分别为微博用户的唯一 id、微博用户的唯一 id、第几度人脉。
3 选择具体实现思路
先自己手机微博客户端抓包,得到数据包并配置到代码中去,查看其中的 URL:

其中需要的 URL 如:https://api.weibo.cn/2/friendships/bilateral?aid=XXX.&c=weicoabroad&count=50&from=XXX&gsid=XXX&i=XXX&lang=zh_CN&page=1&real_relationships=1&s=XXX&trim_status=1&ua=iPhone6%2C1_iOS12.2_Weibo_intl._3450_wifi&uid=用户&v_p=XXX在爬虫代码中利用此 URL,获取到互关好友的数据(json 文件)。
分析这些 json 文件,提取其中的信息,写入到 CSV 文件。
4 爬虫程序编写前准备
- 了解 Python 项目的目录结构:
- 有趣的Python爬虫和Python数据分析小项目
- python基础6–目录结构
- 开篇python–明白python文件如何组织,理解建立源文件
- Open Sourcing a Python Project the Right Way
1 | weibo-friends-analysis/ |
- 注意:怎样爬信息参见我的博文 《通过微博手机客户端爬取数据的分析》,因为通过手机客户端抓包分析,可以通过构造的 URL 直接得到用户互关好友数据,所以不需要模拟登陆。
- 安装需要的库,项目根目录生成 requirements.txt 来记录需要的库,
pip freeze > requirements.txt,安装的话pip install -r requirements.txt。
五 数据获取到分析流程
使用 WFACat 来获取基本数据 -> 生成节点、边文件 -> 写入数据库 -> 数据清洗写入数据库
使用 Gephi 数据可视化分析软件分析节点与边
使用
mysqld命令查询 WFACat 数据分析的结果使用 Tableau 数据可视化分析 WFACat 清洗过的数据
六 项目整理文章汇总
注意:
以上分析写的文章并非项目最终的样子,因为这中间更改了很多方案。以上只是最开始的记录,没有舍得删掉已经写的大段文字。
整个 WAFCat 项目涉及的内容写成了多篇文章,以下列出的这些我实践过程中写的文章,才是此项目真正的所有分析文章。
